 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSR$^{2}$-Net: A General Plug-and-Play Model for Spectral Refinement in Hyperspectral Image Super-Resolution
Jan 29, 2026HSI-SR aims to enhance spatial resolution while preserving spectrally faithful and physically plausible characteristics. Recent methods have achieved great progress by leveraging spatial correlations to enhance spatial resolution. However, these methods often neglect spectral consistency across bands, leading to spurious oscillations and physically implausible artifacts. While spectral consistency can be addressed by designing the network architecture, it results in a loss of generality and flexibility. To address this issue, we propose a lightweight plug-and-play rectifier, physically priors Spectral Rectification Super-Resolution Network (SR$^{2}$-Net), which can be attached to a wide range of HSI-SR models without modifying their architectures. SR$^{2}$-Net follows an enhance-then-rectify pipeline consisting of (i) Hierarchical Spectral-Spatial Synergy Attention (H-S$^{3}$A) to reinforce cross-band interactions and (ii) Manifold Consistency Rectification (MCR) to constrain the reconstructed spectra to a compact, physically plausible spectral manifold. In addition, we introduce a degradation-consistency loss to enforce data fidelity by encouraging the degraded SR output to match the observed low resolution input. Extensive experiments on multiple benchmarks and diverse backbones demonstrate consistent improvements in spectral fidelity and overall reconstruction quality with negligible computational overhead. Our code will be released upon publication.
Physical Prompt Injection Attacks on Large Vision-Language Models
Jan 24, 2026Large Vision-Language Models (LVLMs) are increasingly deployed in real-world intelligent systems for perception and reasoning in open physical environments. While LVLMs are known to be vulnerable to prompt injection attacks, existing methods either require access to input channels or depend on knowledge of user queries, assumptions that rarely hold in practical deployments. We propose the first Physical Prompt Injection Attack (PPIA), a black-box, query-agnostic attack that embeds malicious typographic instructions into physical objects perceivable by the LVLM. PPIA requires no access to the model, its inputs, or internal pipeline, and operates solely through visual observation. It combines offline selection of highly recognizable and semantically effective visual prompts with strategic environment-aware placement guided by spatiotemporal attention, ensuring that the injected prompts are both perceivable and influential on model behavior. We evaluate PPIA across 10 state-of-the-art LVLMs in both simulated and real-world settings on tasks including visual question answering, planning, and navigation, PPIA achieves attack success rates up to 98%, with strong robustness under varying physical conditions such as distance, viewpoint, and illumination. Our code is publicly available at https://github.com/2023cghacker/Physical-Prompt-Injection-Attack.
Evaluating the encoding competence of visual language models using uncommon actions
Jan 12, 2026We propose UAIT (Uncommon-sense Action Image-Text) dataset, a new evaluation benchmark designed to test the semantic understanding ability of visual language models (VLMs) in uncommon-sense action scenes. Unlike previous datasets that focus on common visual scenes with statistical frequency advantages, UAIT challenges models with grammatically reasonable but semantically counter-common sense image-text pairs. Such tasks require models to go beyond superficial pattern recognition and demonstrate a deep understanding of agent-patient relationships and physical feasibility. To build UAIT, we designed a semi-automated process to synthesize high-quality uncommon-sense image-text samples using large language models, few-shot prompt engineering, and text-to-image generation. Each sample is accompanied by a carefully designed multiple-choice question to test the model's competence in fine-grained reasoning. We evaluate multiple state-of-the-art visual language models and compare them with models based on contrastive learning. Experiments show that all models perform significantly worse than humans in semantic judgment, especially in distinguishing grammatical correctness from semantic rationality. Further experiments show that even the lightweight model can improve its accuracy after fine-tuning, demonstrating the great potential of directional adaptation. This study not only reveals the key weaknesses of VLMs, but also provides diagnostic tools and research directions for the development of robust models with real visual semantic reasoning capabilities.
M2SE: A Multistage Multitask Instruction Tuning Strategy for Unified Sentiment and Emotion Analysis
Dec 11, 2024



Sentiment analysis and emotion recognition are crucial for applications such as human-computer interaction and depression detection. Traditional unimodal methods often fail to capture the complexity of emotional expressions due to conflicting signals from different modalities. Current Multimodal Large Language Models (MLLMs) also face challenges in detecting subtle facial expressions and addressing a wide range of emotion-related tasks. To tackle these issues, we propose M2SE, a Multistage Multitask Sentiment and Emotion Instruction Tuning Strategy for general-purpose MLLMs. It employs a combined approach to train models on tasks such as multimodal sentiment analysis, emotion recognition, facial expression recognition, emotion reason inference, and emotion cause-pair extraction. We also introduce the Emotion Multitask dataset (EMT), a custom dataset that supports these five tasks. Our model, Emotion Universe (EmoVerse), is built on a basic MLLM framework without modifications, yet it achieves substantial improvements across these tasks when trained with the M2SE strategy. Extensive experiments demonstrate that EmoVerse outperforms existing methods, achieving state-of-the-art results in sentiment and emotion tasks. These results highlight the effectiveness of M2SE in enhancing multimodal emotion perception. The dataset and code are available at https://github.com/xiaoyaoxinyi/M2SE.
Enhancing Security Control Production With Generative AI
Nov 06, 2024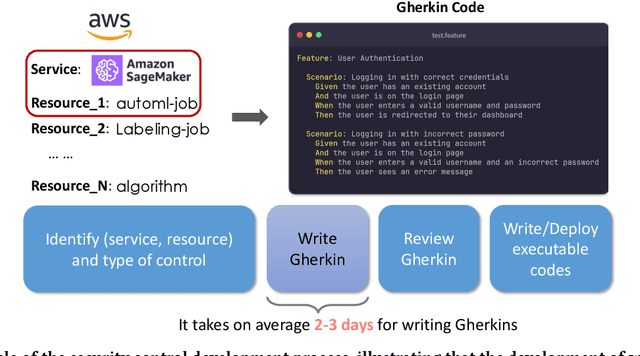

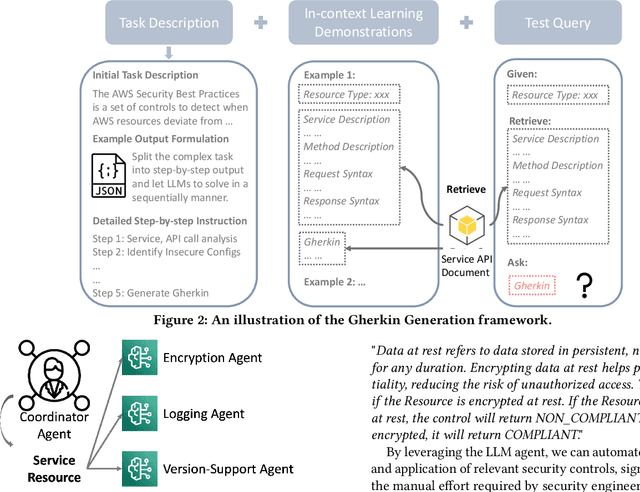
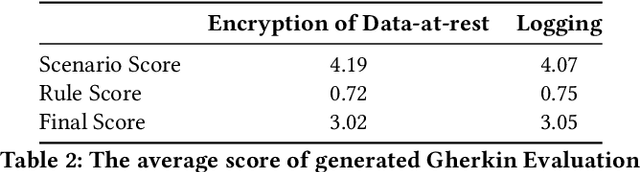
Security controls are mechanisms or policies designed for cloud based services to reduce risk, protect information, and ensure compliance with security regulations. The development of security controls is traditionally a labor-intensive and time-consuming process. This paper explores the use of Generative AI to accelerate the generation of security controls. We specifically focus on generating Gherkin codes which are the domain-specific language used to define the behavior of security controls in a structured and understandable format. By leveraging large language models and in-context learning, we propose a structured framework that reduces the time required for developing security controls from 2-3 days to less than one minute. Our approach integrates detailed task descriptions, step-by-step instructions, and retrieval-augmented generation to enhance the accuracy and efficiency of the generated Gherkin code. Initial evaluations on AWS cloud services demonstrate promising results, indicating that GenAI can effectively streamline the security control development process, thus providing a robust and dynamic safeguard for cloud-based infrastructures.
HiReview: Hierarchical Taxonomy-Driven Automatic Literature Review Generation
Oct 02, 2024In this work, we present HiReview, a novel framework for hierarchical taxonomy-driven automatic literature review generation. With the exponential growth of academic documents, manual literature reviews have become increasingly labor-intensive and time-consuming, while traditional summarization models struggle to generate comprehensive document reviews effectively. Large language models (LLMs), with their powerful text processing capabilities, offer a potential solution; however, research on incorporating LLMs for automatic document generation remains limited. To address key challenges in large-scale automatic literature review generation (LRG), we propose a two-stage taxonomy-then-generation approach that combines graph-based hierarchical clustering with retrieval-augmented LLMs. First, we retrieve the most relevant sub-community within the citation network, then generate a hierarchical taxonomy tree by clustering papers based on both textual content and citation relationships. In the second stage, an LLM generates coherent and contextually accurate summaries for clusters or topics at each hierarchical level, ensuring comprehensive coverage and logical organization of the literature. Extensive experiments demonstrate that HiReview significantly outperforms state-of-the-art methods, achieving superior hierarchical organization, content relevance, and factual accuracy in automatic literature review generation tasks.
PIXELMOD: Improving Soft Moderation of Visual Misleading Information on Twitter
Jul 30, 2024



Images are a powerful and immediate vehicle to carry misleading or outright false messages, yet identifying image-based misinformation at scale poses unique challenges. In this paper, we present PIXELMOD, a system that leverages perceptual hashes, vector databases, and optical character recognition (OCR) to efficiently identify images that are candidates to receive soft moderation labels on Twitter. We show that PIXELMOD outperforms existing image similarity approaches when applied to soft moderation, with negligible performance overhead. We then test PIXELMOD on a dataset of tweets surrounding the 2020 US Presidential Election, and find that it is able to identify visually misleading images that are candidates for soft moderation with 0.99% false detection and 2.06% false negatives.
TEG-DB: A Comprehensive Dataset and Benchmark of Textual-Edge Graphs
Jun 14, 2024



Text-Attributed Graphs (TAGs) augment graph structures with natural language descriptions, facilitating detailed depictions of data and their interconnections across various real-world settings. However, existing TAG datasets predominantly feature textual information only at the nodes, with edges typically represented by mere binary or categorical attributes. This lack of rich textual edge annotations significantly limits the exploration of contextual relationships between entities, hindering deeper insights into graph-structured data. To address this gap, we introduce Textual-Edge Graphs Datasets and Benchmark (TEG-DB), a comprehensive and diverse collection of benchmark textual-edge datasets featuring rich textual descriptions on nodes and edges. The TEG-DB datasets are large-scale and encompass a wide range of domains, from citation networks to social networks. In addition, we conduct extensive benchmark experiments on TEG-DB to assess the extent to which current techniques, including pre-trained language models, graph neural networks, and their combinations, can utilize textual node and edge information. Our goal is to elicit advancements in textual-edge graph research, specifically in developing methodologies that exploit rich textual node and edge descriptions to enhance graph analysis and provide deeper insights into complex real-world networks. The entire TEG-DB project is publicly accessible as an open-source repository on Github, accessible at https://github.com/Zhuofeng-Li/TEG-Benchmark.
TAGA: Text-Attributed Graph Self-Supervised Learning by Synergizing Graph and Text Mutual Transformations
May 27, 2024



Text-Attributed Graphs (TAGs) enhance graph structures with natural language descriptions, enabling detailed representation of data and their relationships across a broad spectrum of real-world scenarios. Despite the potential for deeper insights, existing TAG representation learning primarily relies on supervised methods, necessitating extensive labeled data and limiting applicability across diverse contexts. This paper introduces a new self-supervised learning framework, Text-And-Graph Multi-View Alignment (TAGA), which overcomes these constraints by integrating TAGs' structural and semantic dimensions. TAGA constructs two complementary views: Text-of-Graph view, which organizes node texts into structured documents based on graph topology, and the Graph-of-Text view, which converts textual nodes and connections into graph data. By aligning representations from both views, TAGA captures joint textual and structural information. In addition, a novel structure-preserving random walk algorithm is proposed for efficient training on large-sized TAGs. Our framework demonstrates strong performance in zero-shot and few-shot scenarios across eight real-world datasets.
GRAG: Graph Retrieval-Augmented Generation
May 26, 2024



While Retrieval-Augmented Generation (RAG) enhances the accuracy and relevance of responses by generative language models, it falls short in graph-based contexts where both textual and topological information are important. Naive RAG approaches inherently neglect the structural intricacies of textual graphs, resulting in a critical gap in the generation process. To address this challenge, we introduce $\textbf{Graph Retrieval-Augmented Generation (GRAG)}$, which significantly enhances both the retrieval and generation processes by emphasizing the importance of subgraph structures. Unlike RAG approaches that focus solely on text-based entity retrieval, GRAG maintains an acute awareness of graph topology, which is crucial for generating contextually and factually coherent responses. Our GRAG approach consists of four main stages: indexing of $k$-hop ego-graphs, graph retrieval, soft pruning to mitigate the impact of irrelevant entities, and generation with pruned textual subgraphs. GRAG's core workflow-retrieving textual subgraphs followed by soft pruning-efficiently identifies relevant subgraph structures while avoiding the computational infeasibility typical of exhaustive subgraph searches, which are NP-hard. Moreover, we propose a novel prompting strategy that achieves lossless conversion from textual subgraphs to hierarchical text descriptions. Extensive experiments on graph multi-hop reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods while effectively mitigating hallucinations.